Save money at scale with prompt caching
Are you thinking about launching a new LLM-powered service to millions of users a day?
Have you done the math to figure out how much that will cost you?
It’s not cheap, but here is a quick tip that could save you a decent amount of money while decreasing request latency.
Let me introduce you to the concept of Prompt Caching.
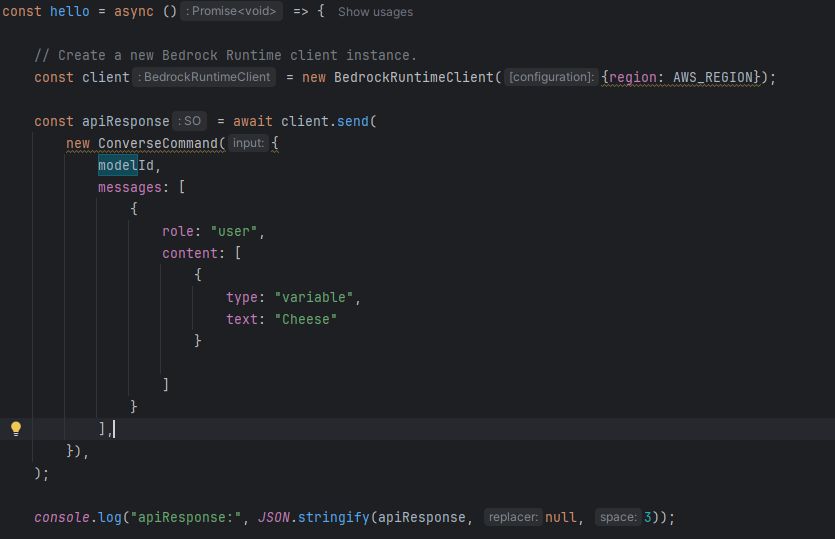
What you can do is create a cachePoint that caches the content blocks leading up to it in memory for a minimum of 5 minutes. This time period extends with each successful
subsequent call.
According to the AWS Bedrock Pricing Page: “Cache read input tokens will be 75% less than on-demand input token price”. So we are not talking peanuts on savings.
When you factor in that you can cache images, and not only do you not have to send that image across the web with each new chat message, but you will get that lovely 75% discount on that massive amount of tokens, this really could have a profound impact on your AWS bill.
Question for you:
Are you using conversational AI? If so, how are you preventing your bills from exploding?