You have heard of RAG (Retrieval-Augmented Generation), but have you heard of V-RAG?
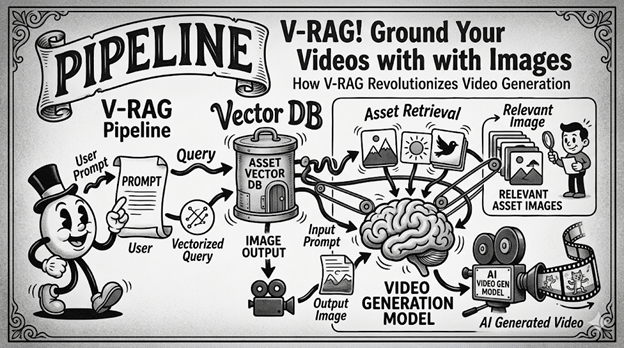
V-RAG, or Video Retrieval-Augmented Generation, is a technique for grounding video generation models using static images it queries from a vector DB/Index of static images.
I know it sounds complicated and, if you asked me a few years ago, before I went deep down the rabbit hole of RAG and Vector DBs, I would have agreed, but in reality, it's relatively simple.
Just feeding in text to a text-to-video model and hoping it will output what you want leaves plenty of room for error.
With this technique, you send your input text to an embedding model that will convert it to a vector.
That vector will be used to grab a handful of binary images relating to your query from a vector DBA great use case for S3 Vector Indexes.
You then send those images to the video generation model along with the prompt to help improve the final result.
I suppose you could improve your outcome by adding a step after you have retrieved the images, but before you send them off to the model, where a human could cross-check the images and perhaps add some additional context to the images to make sure they showed up in order and were being used… or you could just send them. Your call.
So there you have V-RAG.
Question for you:
What other adaptations of RAG (Retrieval-Augmented Generation) have you seen?
PS: Had some fun with the image for this one. As always, I do the writing and my EA proofs it, but the image is AI. Let me know what you think.